



If you have been reading the headlines over the last few months, you might be convinced that the global AI landscape has already tilted irreversibly eastward. Chinese frontier models — specifically the latest iterations from DeepSeek, Qwen, and MiniMax — are dominating standardized testing leaderboards.
They are crushing the MMLU, obliterating standard coding benchmarks, and scoring exceptionally high on advanced math datasets like MATH and GSM8K. Furthermore, they are achieving these results with highly optimized training runs, utilizing advanced Mixture of Experts (MoE) architectures that cost a fraction of what Silicon Valley tech giants are spending on their server farms. On paper, it looks like a total victory for efficient scaling.
But when you strip away the generalized testing environments and thrust these exact same “state-of-the-art” systems into the unforgiving arena of the ARC-AGI-2 benchmark, the triumphant narrative begins to collapse.
The ARC-AGI-2 (Abstraction and Reasoning Corpus) was formulated by AI researcher François Chollet, and it was designed specifically to be resistant to the brute-force memorization that Large Language Models (LLMs) inherently rely upon. Based on recent data from early 2026, the most prominent Chinese models are scoring poorly on ARC-AGI-2 compared to top-tier Western frontier models. In fact, they are often lagging behind by an estimated 8 months in pure abstract reasoning capabilities.
If we are serious about the actual trajectory toward Artificial General Intelligence (AGI) — rather than just building increasingly powerful autocomplete engines — this particular benchmark is the mirror exposing the industry’s deepest flaws. It is brutally illustrating the fundamental difference between a highly optimized “next-token predictor” and a system capable of actual, generalized fluid intelligence.
Understanding ARC-AGI: The Benchmark That Cannot Be Memorized
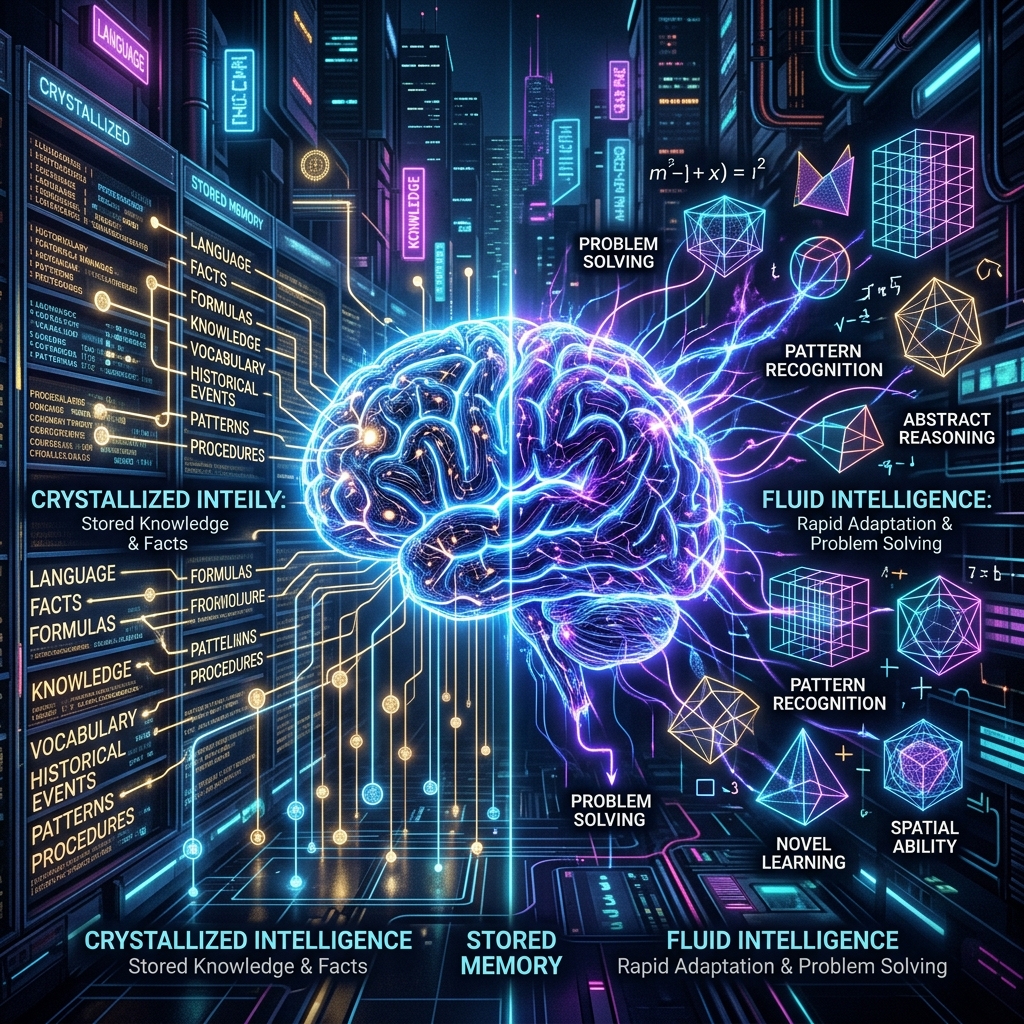
To genuinely grasp why models like DeepSeek or Qwen are failing this test, you have to understand what makes ARC-AGI so diabolical to a language model.
If you are not intimately familiar with it, ARC-AGI-2 is not like testing an AI on the unified bar exam, or making it write a Python script for a sorting algorithm. Standard benchmarks, by and large, measure crystallized intelligence. This is the ability to recall, synthesize, and reformulate data distributions that the model has already encountered during its massive pre-training phase. If the model has ingested millions of GitHub repositories, it will write flawless code. If it has parsed Wikipedia a thousand times, it will regurgitate historical facts with pinpoint accuracy. LLMs are, fundamentally, digital gods of crystallized intelligence.
ARC, however, measures fluid intelligence. This is the inherent ability to rapidly adapt to entirely novel task environments, understand abstract underlying rules with minimal examples (often just two or three), and then apply those logical rules to essentially alien situations. Chollet designed it with a core philosophy: “Easy for humans, hard for AI.”
When the original ARC-AGI-1 evolved into version 2 in 2025, it expanded significantly. It added complex symbolic interpretation, multi-step compositional reasoning, and heavier contextual rule application. Most importantly, it introduced a metric of efficiency. The benchmark no longer just asks if the AI can eventually stumble upon the right answer after consuming thousands of compute cycles in a massive chain-of-thought loop; it asks if the AI can deduce the answer efficiently, much like a human brain does.
Why does this matter? Because you simply cannot scale your way out of an ARC-AGI test suite. No amount of compute, no amount of synthetic data generation, and no amount of parameter-count bloat can save a model that fundamentally does not know how to induce reasoning from a blank slate.
The Illusion of the Autoregressive Architecture

Over the past year, models like Qwen and GLM-4 Flash have perfected their architectures through techniques like aggressive distillation, hyper-efficient MoE routing, and utilizing highly refined synthetic data generated by larger teacher models. They have figured out how to extract every ounce of performance from finite hardware, which has been incredibly disruptive to Western dominance.
However, the architecture they rely upon is autoregressive. LLMs are probabilistic engines designed to generate coherent text by predicting the next most statistically likely token based on a massive context window. They do not maintain a permanent external state of logical truth, nor do they possess an internal dynamic workspace to test hypotheses before committing them to the output stream.
When presented with an ARC-AGI-2 grid puzzle:
– The Extrapolation Failure: They critically struggle to infer underlying geometric symmetries, rigid body transformations, or abstract symbolic translations when they haven’t seen a direct semantic analog for it in their training data.
– Pattern Matching Clashing with Reasoning: Because they are hardwired to look for learned patterns, they default to pattern-matching algorithms, confidently generating visual grid answers that look statistically plausible but are logically completely nonsensical.
– The “Forward-Only” Trap: An LLM generates text from left to right. When it makes a subtle logical error early in its symbolic reasoning chain, it often lacks the architectural mechanism to pause, backtrack, erase its error, and try a different spatial hypothesis. It simply doubles down on the hallucination and barrels forward toward a failed answer.
The Reality of the Chinese Frontier on ARC-AGI-2
So what do the actual numbers tell us about the Chinese frontier models?
As of early 2026, leading models out of China are reportedly scoring remarkably low on ARC-AGI-2. While the absolute best models from OpenAI and Anthropic are fighting to break past the mid-double digits on various iterations of the test, the Chinese counterparts are hovering in the single digits or low teens.
This creates a fascinating — and arguably concerning — dichotomy.
On one hand, you have DeepSeek engineering brilliant workarounds to physical hardware limitations, proving that you do not need 100,000 top-tier NVIDIA GPUs to train a model that can out-code a mid-level software engineer. On the other hand, the data wall is hitting them exceedingly hard when it comes to true abstract logic.
The low scores reflect a harsh truth: dumping more high-quality synthetic data into the pre-training pipeline does not magically instantiate a reasoning engine. It simply makes a better pattern-matching engine. The “China AI breakthrough” that has dominated tech media is currently hyper-focused on efficiency and optimizing for established, Western-defined test sets. It is a triumph of engineering and resourcefulness, absolutely. But it is not a triumph of pioneering new paradigms of abstract logic.
Modality Mismatch: Language vs. Spatial Reality

One of the persistent arguments regarding why language models fail at ARC-AGI is the problem of modality. The benchmark consists of brightly colored 2D grids. Humans look at these grids and instantaneously recognize concepts like “inside,” “outside,” “border,” “symmetry,” and “movement.” Our brains have been shaped by millions of years of evolution to navigate a three-dimensional spatial reality.
When these visual problems are fed into an LLM (either via vision encoders or translated into raw text matrices), the model is attempting to solve a deeply spatial problem using neurological pathways optimized for linguistic grammar.
We are essentially asking a specialized dictionary to solve a Rubik’s Cube.
The models try to parse the grid as a sequence of symbols to predict, rather than understanding that a cluster of blue pixels represents an “object” that maintains its structural integrity as it moves across a black pixel canvas. The absolute failure of these models to maintain “object permanence” in a basic 2D grid matrix highlights why they are so incredibly far from being able to manage a complex, multi-variable real-world environment.
Examining ARC-AGI-3 and Test-Time Adaptation
The landscape is not sitting still. If ARC-AGI-2 exposes the limits of static inference, the newly released ARC-AGI-3 is an outright massacre of current paradigms.
ARC-AGI-3 moves away from static reasoning tasks and introduces deeply interactive environments. It requires an AI agent to actively explore a space, test actions, receive feedback, and learn from its failures dynamically. It is essentially asking the model to perform the scientific method in real-time.
As of late March 2026, the top frontier models globally — including the absolute best from OpenAI, Google, and Anthropic — are scoring significantly below 1% on this new version. It is a total wipeout.
The immediate takeaway from both ARC-AGI-2 and ARC-AGI-3 is that the entire global AI industry must pivot heavily toward Test-Time Compute and dynamic search algorithms. If pre-training is hitting a wall of diminishing returns, the only way forward is allowing models to “think” longer during inference. They need to spawn agentic workflows that can draft a hypothesis, test it in an isolated sandbox, recognize failure, and iterate on a completely new strategy without hallucinating.
While Western labs are already beginning to experiment with these inference-time reasoning architectures (evident in the slower, more deliberate thinking models released recently), the current highly-distilled, ultra-fast Chinese models are heavily optimized for immediate, low-latency token generation. This architectural choice makes them incredible for rapid deployment in consumer products, but it acts as an anchor when deep, sustained, multi-branched logical search is required.
The Hardware Wars and AGI Timelines

So, where does this leave the geopolitical hardware wars and the race to Artificial General Intelligence?
First, it validates the strategy of those pushing for enormous, centralized compute clusters for the next generation of foundational models. While Chinese efficiency is commendable and allows them to democratize AI on local consumer hardware, solving fluid intelligence will likely require a completely new architecture — one that bridges the gap between deep RL (Reinforcement Learning) agents and massive language encoders. Training this hypothetical new architecture from scratch will demand compute capabilities that are heavily restricted by current export bans.
Secondly, it serves as a massive reality check for the AGI timeline. If you define AGI as merely the automation of white-collar digital labor (writing emails, summarizing PDFs, generating boilerplate Python code), then AGI is basically already here. The latest open-source and proprietary models are more than sufficient to upend the modern knowledge economy.
However, if you define AGI as actual generalized intelligence — a system that can be dropped into an entirely novel domain, absorb the rules dynamically, and begin solving problems better than a human without ever having seen the domain before — we are not even close.
The performance gap between Western and Chinese models on ARC-AGI-2 is fascinating, not because it proves US dominance, but because it highlights two different optimization strategies. The West is still blindly trying to bash its way through the reasoning wall with sheer compute volume, eking out slight percentage gains on ARC logic. China has largely accepted the current architectural limits and focused entirely on making those limits run as cheaply and efficiently as possible.
Conclusion
As we continue to meticulously track and evaluate the capabilities of AI models through 2026, it is vital to look past the standard headlines. Hitting 90% on a coding benchmark is a display of breathtaking engineering data curation. But figuring out a novel visual logic puzzle without ever being explicitly taught how to solve it? That is the hallmark of actual intelligence.
Until a model can consistently beat humans at the ARC-AGI benchmarks without relying on brute-force millions of sample generations, we are still dealing with incredibly sophisticated parrots. The reality of Chinese models — and indeed, the reality of all current LLMs — is that they are masters of the crystalized past, but remain deeply confused by the fluid, adaptable requirements of the unseen future.
The AGI hype train needs to slow down, take a long look at these brilliantly simple colored grids, and realize that we might still be at step one of a very, very long staircase.
Har Har Mahadev 🔱, Jai Maa saraswati🌺