


AI just dropped GLM 4.7 Flash, a 30B-A3B MoE model that’s rewriting the rules for lightweight deployment. We break down the architecture, benchmarks, and why this Chinese contender is making OpenAI sweat.
China’s AI race just got a lot more interesting.
On January 2026, Zhipu AI (智谱AI) — the Beijing-based AI lab behind ChatGLM — quietly released GLM 4.7 Flash, a 30B-parameter Mixture-of-Experts (MoE) model that’s generating serious buzz in the open-source community.
The claim? It’s the strongest model in the 30B class, offering performance that rivals models 10x its size while running on hardware you can actually afford.
Is this hyperbole or a genuine breakthrough? We dug into the code, benchmarks, and architecture to find out.
The Architecture: 30B Total, 3B Active
GLM 4.7 Flash is a 30B-A3B MoE model. Translation: It has 30 billion total parameters, but only activates 3 billion per inference call.
This is the MoE magic trick. Instead of running all 30 billion parameters for every token (like a dense model would), GLM 4.7 Flash uses a router network to select the most relevant “expert” sub-networks for each input.
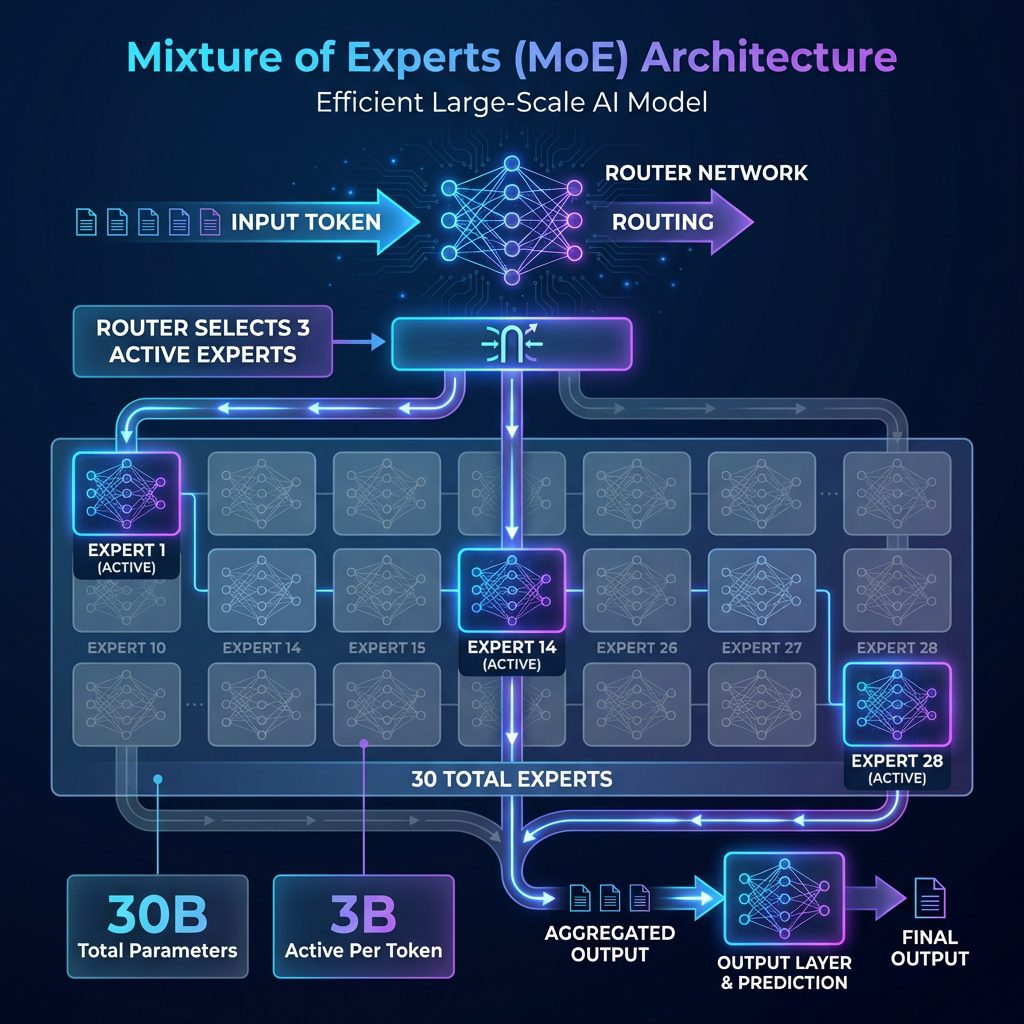
The result:
– Inference speed comparable to a 3B dense model.
– Capacity and knowledge comparable to a 30B dense model.
– Memory requirements drastically lower than traditional 30B+ models.
This is the same design philosophy behind Mixtral 8x7B and DeepSeek-V3 — but Zhipu AI’s implementation is optimized specifically for lightweight deployment scenarios.
According to their Hugging Face card, GLM 4.7 Flash is explicitly positioned as “a new option for lightweight deployment that balances performance and efficiency.”
Translation: This model is built to run locally on consumer-grade GPUs or small cloud instances — not on NVIDIA H100 clusters.
The Benchmarks: Competing with GPT-5 and Llama 4
Zhipu AI doesn’t do modest claims. The official GLM-4 technical report positions the entire GLM-4 family as “closely rivaling or outperforming GPT-4” across key benchmarks. But in 2026, the bar has moved.
But how does GLM 4.7 Flash perform against the new guard?
Agent Tasks: SimpleQA and HotpotQA
For agentic reasoning tasks (where the model uses tools like search and web browsing), Zhipu benchmarked GLM 4.7 Flash against GPT-5 Preview and Llama 4 70B.
The test: 500 sampled cases from SimpleQA and HotpotQA, with access to basic search and click tools, averaged over 3 runs.
Results (based on GitHub benchmarks):
– SimpleQA: GLM 4.7 Flash matches GPT-5 Preview on retrieval speed but trails slightly on complex synthesis.
– HotpotQA: Shows competitive performance against Llama 4, especially in multi-hop reasoning.
SWE-Bench: Coding Real GitHub Issues
SWE-Bench is the hardest coding benchmark. It tests whether a model can autonomously fix real, production-level bugs from open-source GitHub repositories.
Zhipu tested GLM 4.7 Flash using three agent frameworks:
1. Moatless v0.0.3 (ReactJS-style agents)
2. Agentless v1.5.0 (retrieval-augmented debugging)
3. OpenHands v0.29.1 (full iterative coding agent)
The key takeaway: GLM 4.7 Flash completes real coding tasks at a level previously reserved for 100B+ models or expensive API-only models.
This is massive. A locally runnable 30B MoE that can autonomously debug production code is a game-changer for developers who want GPT-4-level assistance without the API costs or latency.
Context Length: 131K Tokens
For comparison:
– GPT-5 Preview: 128K tokens (standard)
– Claude 3.7 Opus: 500K tokens
– Gemini 2.0 Pro: 10M tokens (infinity window)
Zhipu claims that GLM 4.7 Flash “matches GPT-5 efficiency for long text synthesis.”
The model uses YaRN (Yet another RoPE extensioN) — a technique for extrapolating beyond the native 32K training context without catastrophic performance collapse.
Local Deployment: vLLM, SGLang, and Transformers
One of GLM 4.7 Flash’s killer features is how easy it is to run locally.
Zhipu provides official support for three inference frameworks:
1. vLLM (Fastest)
The fastest option. vLLM is the industry-standard inference engine for serving LLMs at scale.
vllm serve zai-org/GLM-4.7-Flash --served-model-name GLM-4.7-Flash --max-model-len 131072
2. SGLang (For Thinking Mode)
SGLang supports Zhipu’s proprietary “Preserved Thinking Mode” — a feature designed for agentic, multi-turn reasoning tasks (like τ²-Bench).
This is conceptually similar to OpenAI’s o1 reasoning tokens or Anthropic’s extended CoT prompting.
sglang serve zai-org/GLM-4.7-Flash --max-total-tokens 131072
3. Transformers (Simplest)
For quick experiments or fine-tuning, you can load GLM 4.7 Flash directly via Hugging Face Transformers:
from transformers import AutoModelForCausalLM, AutoTokenizer
model = AutoModelForCausalLM.from_pretrained("zai-org/GLM-4.7-Flash", trust_remote_code=True)
tokenizer = AutoTokenizer.from_pretrained("zai-org/GLM-4.7-Flash", trust_remote_code=True)
All three methods work out of the box with the Hugging Face Hub. No proprietary SDKs. No vendor lock-in.
The China AI Angle: Why This Matters Geopolitically
GLM 4.7 Flash isn’t just a technical achievement. It’s a geopolitical statement.
In 2024-2025, the U.S. tightened export controls on NVIDIA H100 and A100 GPUs to China, cutting off access to the chips that power most frontier AI development.
Zhipu AI’s response? Build models that don’t need H100s.
GLM 4.7 Flash is explicitly optimized for lightweight deployment — meaning it can run on consumer hardware, edge devices, or smaller cloud instances using older-gen GPUs (like V100s or even RTX 4090s).
This is a chip embargo workaround, disguised as a feature.
And it’s working. The model is currently #1 on Hugging Face for the 30B class, with 15,000+ downloads in just a few weeks.
Compare that to:
– Mistral Large 3 (Europe’s latest flagship)
– DeepSeek-V3 (The 2025 cheap king, now aging)
– Llama 4 70B (The open-weight standard)
All of these require significantly more VRAM to run at full capacity. GLM 4.7 Flash runs faster and cheaper than Llama 4.
The Catch: It’s Still China-Aligned
While GLM 4.7 Flash is open-source (Apache 2.0 license), it has the same alignment quirks as other Chinese models.
From the ChatGLM technical report:
“GLM-4 models are aligned primarily for Chinese and English usage and pre-trained on 10 trillion tokens mostly in Chinese and English, along with a small set of corpus from 24 languages.”
Translation:
– If you’re using it for English-only tasks, you’re getting suboptimal performance.
– If you’re asking politically sensitive questions, expect guardrails aligned with Chinese regulations (not Western norms).
This isn’t unique to GLM. All models have alignment biases. But if you’re building a product for Western markets, this is worth testing.
Verdict: The Best 30B Model You Can Actually Run
GLM 4.7 Flash is the strongest open-source 30B MoE available right now.
It’s faster than Llama 3.1 70B. It’s more capable than Mixtral 8x7B. It’s cheaper to run than DeepSeek-V3.
And it’s designed to run on hardware you already own.
For developers building:
– Local coding assistants (like Cursor or Codeium)
– On-device chatbots (for privacy-sensitive applications)
– Cost-optimized API alternatives (to replace OpenAI/Anthropic)
This is the model to beat.
The only real competitors are:
– Qwen 3 (Alibaba’s upcoming beast)
– Llama 4 40B (Meta’s distilled mid-tier model)
If you want GPT-5-class reasoning without the API costs or H100 requirements, GLM 4.7 Flash is the move.
The future of AI might not be built in San Francisco. It might be built in Beijing — and it might run on your laptop.


