


TL;DR
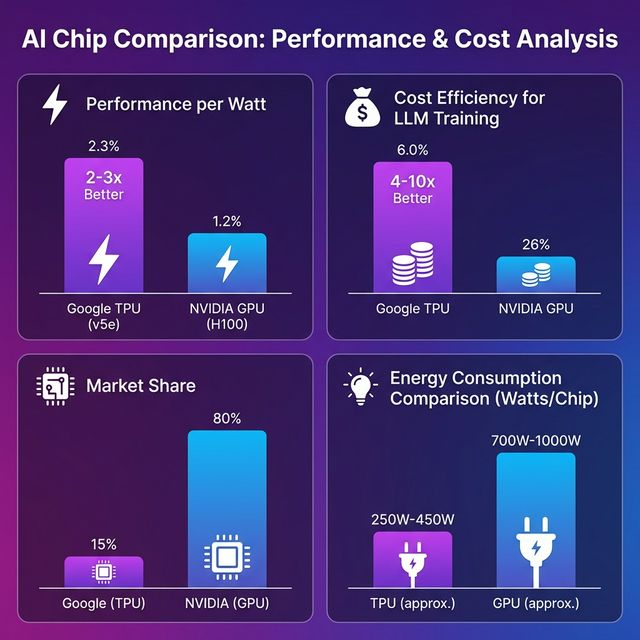
GPUs and TPUs are locked in a battle for AI dominance. GPUs (like NVIDIA’s H100) offer flexibility, broad ecosystem support, and 80% market share. TPUs (Google’s Trillium/v6) deliver 2-3x better performance per watt, 4-10x better cost efficiency for LLM training, and dominate hyperscale inference.
The catch? TPUs only work on Google Cloud and require XLA-compatible models. NVIDIA’s strength: versatility. Google’s bet: specialization wins at scale. Anthropic just ordered 1 million Trillium chips. That’s not a test — that’s a declaration.
Table of Contents
- The Trillion-Dollar Fork in the Road
- Architecture: Why TPUs Are Fast (But Inflexible)
- Performance: The Benchmarks No One Talks About
- Cost: Where TPUs Actually Win
- The CUDA Moat: Why NVIDIA Still Owns 80% of the Market
- Who’s Choosing What (And Why)
- The Future: Hybrid Is Coming
The Trillion-Dollar Fork in the Road
Every AI company faces this decision: train on GPUs or TPUs?
Get it right, save millions. Get it wrong, burn cash on hardware that’s 10x more expensive than it needs to be.
The Stakes in 2026:
- Anthropic: Deploying 1 million+ Google Trillium (TPU v6) chips for Claude
- OpenAI: Rumored to be designing custom ASICs (potentially ditching NVIDIA)
- Meta: Building 600,000-GPU clusters with NVIDIA H100s
- Google: Training Gemini 3 Pro entirely on TPUs
The split tells you everything. Hyperscale players (Google, Anthropic) are betting on TPUs. Everyone else is locked into NVIDIA.
Why?
Architecture: Why TPUs Are Fast (But Inflexible)
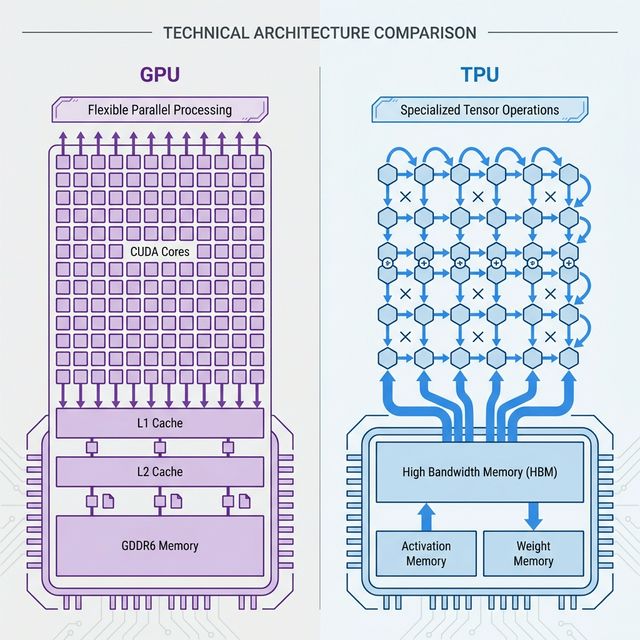
GPUs: The Swiss Army Knife
GPUs were designed for graphics rendering. Thousands of small, programmable cores (CUDA cores on NVIDIA chips) that can handle any parallel computation.
The Flexibility:
- Gaming
- Scientific simulations
- Video encoding
- AI/ML (via Tensor Cores)
NVIDIA’s H100 has 16,896 CUDA cores + dedicated Tensor Cores for matrix multiplication (the core of AI). It’s a general-purpose parallel processor that happens to be good at AI.
The Trade-Off:
Flexibility = overhead. GPUs spend cycles on control logic, memory management, and instruction decoding. That’s wasted power for AI workloads.
TPUs: The Specialist
TPUs are Application-Specific Integrated Circuits (ASICs) built from day one for one thing: tensor operations.
Systolic Arrays:
The secret sauce. Data flows rhythmically through interconnected processing elements. No wasted memory accesses, no complex control overhead.
The Result:
Exceptional throughput for matrix multiplication. 2-3x better performance per watt than GPUs.
The Trade-Off:
Zero flexibility. TPUs can’t render graphics, run scientific simulations, or handle arbitrary code. They do AI, period.
Performance: The Benchmarks No One Talks About
Let’s cut through the marketing BS.
Raw Compute (TFLOPS)
- NVIDIA H100: 156 TFLOPS (FP32), 1,979 TFLOPS (Tensor, FP8)
- Google TPU v5p: 460 TFLOPS (mixed-precision)
- Google TPU v6 (Trillium): 4.7x higher peak performance per chip vs. v5e
TPUs win on paper. But raw TFLOPS is misleading.
Real-World Training Speed
- TPU v3 vs. NVIDIA V100: 8x faster for BERT training, 1.7-2.4x faster for ResNet-50 and LLMs
- TPU v5p vs. H100: Competitive for large-batch LLM training (1M+ tokens), but H100 leads for smaller batches due to higher clock speeds
Why TPUs Win at Scale:
Memory Bandwidth: TPU v5p has 4.8 TB/s. H100 has 3.35 TB/s.
Model FLOPs Utilization (MFU): TPUs hit 58% MFU for LLMs. H100 hits ~52%. Deterministic execution and efficient interconnects matter.
Why GPUs Fight Back:
Small Batch Performance: H100’s higher clock speeds win for real-time inference with small batches.
Dynamic Models: If your model uses dynamic shapes or custom ops, GPUs handle it. TPUs choke.
Energy Efficiency
- TPU v3: 120-150W per chip
- NVIDIA V100: 250W per chip
- NVIDIA A100: 400W per chip
- TPU v4: 200-250W per chip
- NVIDIA H100: 300-350W per chip
TPUs use 2-3x less power for equivalent workloads. At hyperscale (10,000+ chips), that’s millions saved on cooling and electricity.
Cost: Where TPUs Actually Win
This is where it gets interesting.
Training Costs (Large-Scale LLMs):
- TPUs: 4-10x more cost-effective than A100 GPUs
- TPU v5p: 2x higher training performance per dollar vs. TPU v4
- TPU v6e: Up to 4x better performance per dollar vs. H100 (for specific workloads)
Inference Costs (Hyperscale):
TPU v5e: 2.5x higher inference performance per dollar vs. TPU v4
Migrating from GPUs to TPUs: 4x+ cost reduction for LLM serving
The Catch:
These numbers assume:
1. Your model is XLA-compatible
2. You’re running on Google Cloud
3. You’re at scale (tens of thousands of chips)
If you’re training a custom PyTorch model with 8 GPUs in a rack, NVIDIA is cheaper. TPUs win at hyperscale only.
The CUDA Moat: Why NVIDIA Still Owns 80% of the Market
NVIDIA holds 80% of the AI accelerator market. Why?
1. Ecosystem Lock-In
CUDA is everywhere. PyTorch, TensorFlow, JAX, ONNX — they all run on CUDA out of the box.
TPUs require XLA compiler compatibility. If your model has dynamic shapes, custom kernels, or non-standard ops, you’re stuck on GPUs.
2. Multi-Cloud & On-Premise
NVIDIA GPUs are available on:
AWS
Azure
Google Cloud
Oracle Cloud
On-premise data centers
TPUs? Google Cloud only (with rare exceptions for hyperscalers like Anthropic getting custom deployments).
3. Developer Familiarity
Every ML engineer knows CUDA. The tooling, debugging, profiling — it’s all mature.
TPUs feel like Google’s secret sauce. Documentation exists, but the community is smaller.
4. Rapid Prototyping
GPUs let you iterate fast. Try a new architecture, debug, tweak, repeat. TPUs require compiling to XLA first. That’s a friction point.
Who’s Choosing What (And Why)
Choosing GPUs:
Startups: Need multi-cloud flexibility. Can’t afford vendor lock-in.
Research Labs: Experimenting with novel architectures. TPUs are too rigid.
Enterprises with On-Premise: No choice. TPUs aren’t sold for self-hosting (yet).
Gaming/Graphics Hybrid: If you’re doing AI + rendering, GPUs are the only option.
Choosing TPUs:
Google: Obvious. Gemini 3 Pro was trained entirely on TPUs.
Anthropic: 1 million+ Trillium chips for Claude. Betting big on cost savings at scale.
Hyperscale Inference: Companies serving billions of LLM requests (search, recommendations). TPUs’ efficiency wins.
Cost-Sensitive Training: If you’re training 100B+ parameter models, TPUs cut costs by 4-10x.
The Future: Hybrid Is Coming
The next wave: CPU + GPU + TPU clusters.
The Idea:
CPUs: Orchestration, preprocessing
GPUs: Flexible training, dynamic models
TPUs: Hyperscale inference, static LLM serving
Why Hybrid Makes Sense:
Not all workloads are the same. Use the right tool for each phase.
Training on GPUs, inference on TPUs — optimize for both cost and flexibility.
The Challenge:
Distributed systems are hard. Managing heterogeneous clusters is harder.
But the potential savings are too big to ignore.
FAQ
Q: Can I buy TPUs for my own data center?
A: Not easily. Google primarily offers TPUs via Google Cloud. Anthropic got a custom deal for 1 million chips, but that’s hyperscale-only.
Q: Are TPUs faster than GPUs?
A: For large-scale LLM training and inference, yes — 2-3x better performance per watt, 4-10x better cost efficiency. For small batches, dynamic models, or non-AI workloads, GPUs win.
Q: Can I run PyTorch models on TPUs?
A: Yes, via PyTorch/XLA. But not all PyTorch ops are XLA-compatible. Expect friction.
Q: Why doesn’t everyone switch to TPUs if they’re cheaper?
A: Vendor lock-in (Google Cloud only), XLA compatibility issues, smaller ecosystem, and lack of on-premise availability.
Q: What’s NVIDIA’s counter to TPUs?
A: The Blackwell architecture (B100/B200) with 192GB HBM, second-gen Transformer Engine, and native FP4/FP8 precision. Plus the CUDA moat — 80% market share is hard to break.
Q: Will NVIDIA lose the AI chip war?
A: No. Flexibility beats specialization for 80% of use cases. TPUs will dominate hyperscale (Google, Anthropic, Meta-scale players), but NVIDIA owns everyone else.
The Verdict
GPUs are the Swiss Army knife. TPUs are the scalpel.
If you’re training a 500B-parameter LLM and serving 10 billion requests a day, TPUs save millions. If you’re a startup iterating on a custom architecture, NVIDIA is the obvious choice.
The real question: are you willing to bet your company on Google Cloud lock-in?
Anthropic said yes. OpenAI is hedging with custom chips. Meta is doubling down on NVIDIA.
The AI hardware wars are just beginning.
Har Har Mahadev 🔱, Jai Maa saraswati🌺


