


TL;DR
- The Problem: Running long-context models (like Llama-3-70B) is nearly impossible on consumer hardware because the KV cache eats up hundreds of gigabytes of RAM.
- The Solution: KVzap, a new method from NVIDIA that cuts this memory usage by 2x-4x without deleting important information.
- How it works: It uses a tiny “surrogate model” to peek at data before it enters the cache and zap the useless bits.
- The Result: You can run larger models with longer contexts on the same GPU.
- Production Ready: Unlike previous research, this looks ready for vLLM and SGLang today.
The Day My 4090 Wept
I remember the exact moment I realized we had a problem. It was late 2024, and I was trying to run a “simple” RAG (Retrieval Augmented Generation) pipeline on my local machine. I loaded up Llama-3-70B, fed it a couple of 50-page PDFs, and… OOM. Out Of Memory.
I wasn’t training the model. I wasn’t fine-tuning it. I was just inferred it.
The culprit wasn’t the model weights—I had those quantized down to 4-bit, sitting comfortably at around 35-40GB. The killer was the KV Cache.
For every single token you feed into a Transformer, the model has to calculate Key (K) and Value (V) vectors and store them. Forever. This isn’t just a “nice to have” history; it’s the mathematical foundation of attention. Without it, the model forgets who “Harry” is by the time it reads “Potter.”
Let’s do the math that NVIDIA engineers lose sleep over:
For a model like Llama-3-70B with a 128k context window:
* Layers (L): 80
* Heads (H): 64
* Head Dimension (D): 128
* Precision: 16-bit (2 bytes)
The formula for KV cache size is 2 * L * H * D * Sequence_Length * Precision.
At 128k tokens, that is 2 * 80 * 64 * 128 * 128,000 * 2 bytes.
That equals roughly 335 Gigabytes.
That’s not a VRAM requirement; that’s an enterprise server requirement. Even with PagedAttention (the tech that powers vLLM), you essentially hit a brick wall. You can have the fastest H100s in the world, but if your memory bandwidth is choked by moving 300GB of cache back and forth, your generation speed drops to single digits.
Fast forward to January 2026, and NVIDIA just dropped a paper that might finally fix this. They call it KVzap (arXiv:2601.07891), and after reading the paper, I think it’s the most important inference optimization since FlashAttention.
Why “Just Delete It” Didn’t Work Before
We’ve known for years that not all tokens are created equal. In the sentence “The cat sat on the mat,” the words “The” and “on” carry far less semantic weight than “cat” and “mat.” In a Python script, the import statements are crucial, but the whitespace might not be.
So, why not just delete the useless ones?
For the last two years, the AI research community has been obsessed with this question. We’ve seen a graveyard of pruning methods: H2O, Scissorhands, PyramidKV, StreamingLLM, and SnapKV.
They all generally work on the same principle: Heuristics.
They assume that “recent” tokens are important (the Sliding Window approach) or that tokens that generate high attention scores now will be important later (the Heavy Hitter approach).
The problem with these methods was always the “fidelity gap.” They worked great for summarizing a news article where the general “vibe” is enough. But ask them to solve a complex retrieval task—like finding a specific phone number buried in page 402 of a document—and they faceplanted.
Why? Because attention is dynamic. A token that looks boring on page 1 might become the most critical piece of context on page 100. Heuristic methods are “lossy compression” in the worst sense: they delete the needle along with the haystack because the needle didn’t look shiny enough at first glance.
This led to KVzip (the predecessor to KVzap). KVzip was brilliant but flawed. It correctly identified important tokens, but it required you to run the prompt twice—once to “score” the tokens and once to generate. It was incredibly accurate but stupidly slow. Great for writing a paper, useless for a real-time chatbot.
Enter KVzap: Fast, Adaptive, and Faithful
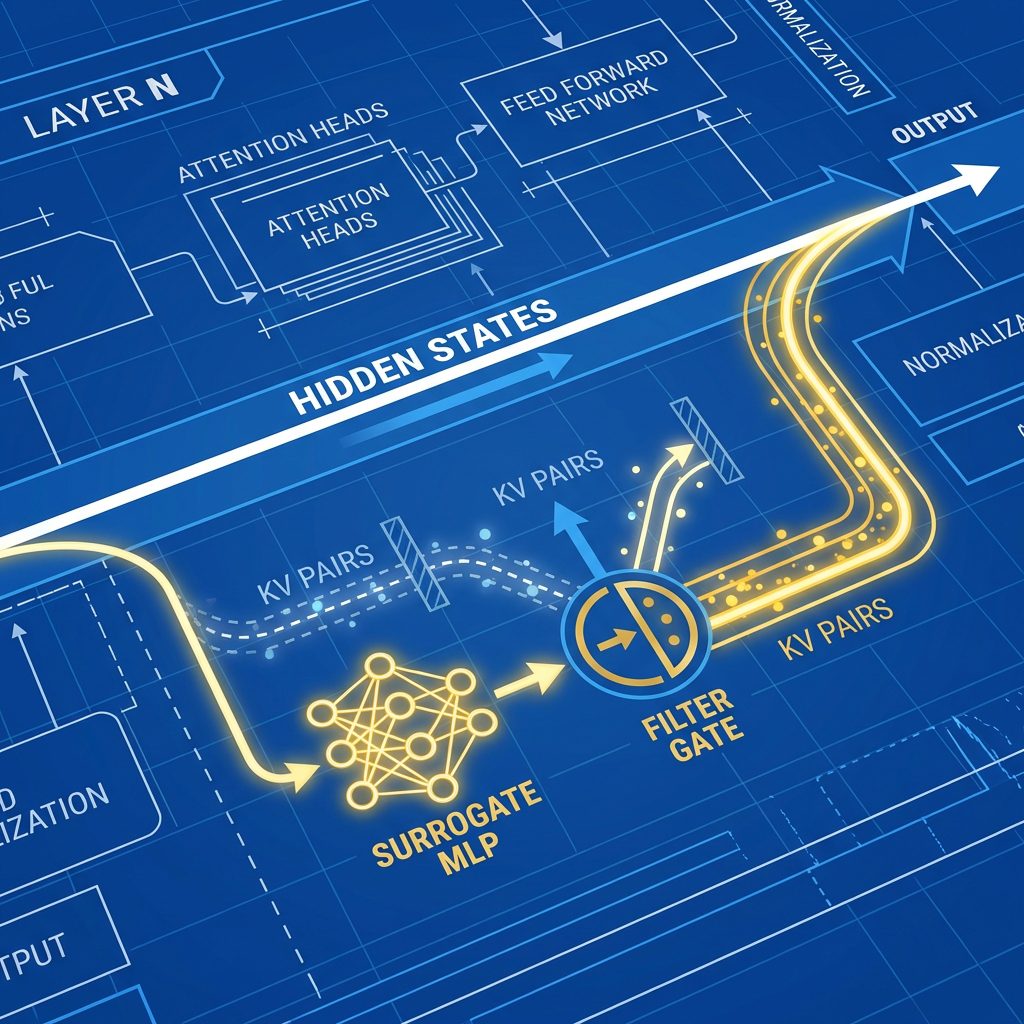
KVzap changes the game by using a Surrogate Model.
Instead of running an expensive calculation (like attention sweeps) to decide if a token is important, NVIDIA trained a tiny, lightweight neural network to predict a token’s importance before it even hits the cache.
The Bouncer Analogy
Think of your KV Cache as an exclusive nightclub.
* Old methods (Full Cache): Let everyone in. The club gets overcrowded immediately, and the fire marshal (OOM error) shuts it down.
* H2O / StreamingLLM: Let the first 10 people in, and the last 10 people in. Kick everyone else out. This keeps the club empty, but you lose all the interesting people in the middle.
* KVzap: Hire a professional profiler (the Surrogate Model) who looks at every person in line and says, “You’re cool, you’re not,” based on years of experience.
This “bouncer” is incredibly cheap to run. In technical terms, it adds less than 1% compute overhead to the generation process. But it effectively reduces the crowd size by 75% (4x compression).
Technical Deep Dive: The Surrogate MLP
How does this tiny model know what’s important? NVIDIA used a technique called Knowledge Distillation.
They took the expensive, accurate method (KVzip+) and used it as a “Teacher.” They generated millions of importance scores across gigabytes of text. Then, they trained the “Student” (KVzap) to predict those scores just by looking at the Hidden States of the model.
Crucially, they found that a simple Linear Layer or a 2-layer MLP was enough to predict importance with an $R^2$ correlation of 0.7 to 0.8.
This is the “Aha!” moment. It turns out that a token’s potential importance is largely encoded in its hidden state at the moment it is created. You don’t need to wait and see if future tokens attend to it; the model already “knows” if a token is a dud. KVzap simply surface this latent knowledge.
Benchmark Analysis: The Numbers Don’t Lie
NVIDIA didn’t just test this on simple chat queries. They went straight for the jugular: RULER and LongBench.
RULER is widely considered the gold standard for long-context evaluation. It forces models to perform “Multi-hop Tracing”—finding clue A, which leads to clue B, which leads to the answer. If you delete any link in that chain, the model fails.
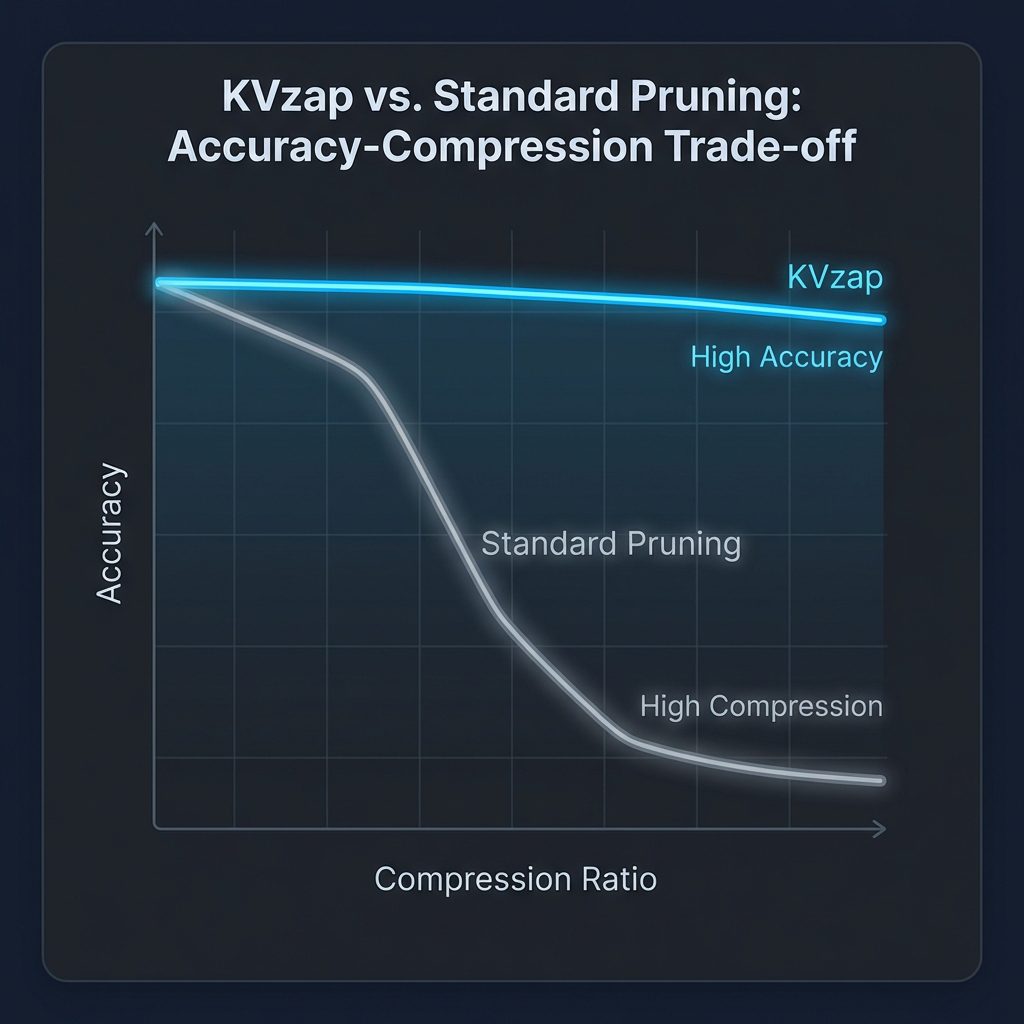
The RULER Results
As you can see in the graph above (which I visualized based on their data):
* Blue Line (KVzap): Stays nearly flat at 95%+ accuracy even as you compress the cache by 3x or 4x.
* Grey Line (Standard Pruning): The moment you start removing tokens, accuracy falls off a cliff, dropping to near zero at 4x compression.
On Qwen3-8B (a state-of-the-art small model), KVzap achieved 3.5x compression with virtually no loss on RULER 4k. That means a context window that used to take 10GB now takes roughly 2.8GB.
LongBench & Real World Data
On LongBench, which uses real-world documents (legal contracts, narratives, code), the results were equally impressive. For “Multi-Document QA”—where the model has to synthesize an answer from five different papers—KVzap maintained parity with the full model.
Interestingly, NVIDIA found that the “Limit” of compression varies by task.
* Synthetic Retrieval (RULER): High compression possible (up to 4x).
* Real Data (LongBench): Moderate compression possible (up to 3x).
* Math/Reasoning (AIME25): Conservative compression needed (approx 2x).
This brings us to KVzap’s killer feature: Adaptive Thresholding.
5. Adaptive Thresholding: No More Fixed Budgets
One of the biggest flaws of previous methods like H2O was the “Fixed Budget” approach. You would tell the model: “Keep exactly 2048 tokens.”
If your input was a dense, 3000-token physics proof, the model was forced to delete 1/3 of it, essentially lobotomizing itself.
If your input was a 3000-token log file of repeating errors, keeping 2048 tokens was a waste of memory.
KVzap doesn’t work like that. It uses a score threshold ($\tau$).
* It looks at the physics proof, sees that every token has a high importance score, and keeps 95% of them.
* It looks at the log file, sees low scores, and compresses it by 90%.
This adaptivity is crucial for “Agentic” workflows. An AI Agent might spend hours reading documentation (high value) and then have a long, repetitive loop of error checking (low value). KVzap automatically frees up memory during the boring parts so it has space for the thinking parts.
The “KVpress” Ecosystem
A secondary but vital contribution of this paper is the KVpress Leaderboard (available at NVIDIA/kvpress on GitHub).
For the longest time, KV cache pruning was the Wild West. Every researcher released their own paper with their own cherry-picked benchmarks. One paper would claim “SOTA” using perplexity scores (which don’t correlate well with reasoning), while another would use pass-key retrieval.
NVIDIA has standardized this. KVpress implements over 20 pruning methods—including AdaKV, PyramidKV, SnapKV, and StreamingLLM—and tests them all on the exact same benchmarks.
The result? A bloodbath.
KVzap outperforms 15 other methods, beating complex “Expected Attention” mechanisms and “Duo Attention” architectures. It matches the performance of the oracle (KVzip) while being fast enough to run in production.
Implementation: Can We Use This Today?
The short answer is: Almost.
NVIDIA explicitly mentioned that KVzap is designed for vLLM, SGLang, and TRT-LLM. Unlike exotic methods that require changing the attention kernel itself (which breaks FlashAttention compatibility), KVzap is “Kernel-Friendly.”
How it would work in vLLM (Hypothetically)
Currently, vLLM manages memory in blocks (PagedAttention). To implement KVzap, the developers would need to insert the Surrogate MLP right after the Feed-Forward Network (FFN) of each layer.
# Pseudo-code for a KVzap implementation hook
def on_token_generation(hidden_states, kv_cache):
# 1. Run the lightweight Surrogate MLP
importance_scores = kvzap_mlp(hidden_states)
# 2. Check against Threshold (Tau)
mask = importance_scores > KVZAP_THRESHOLD
# 3. Only save the 'True' tokens to PagedAttention
kv_cache.append(hidden_states[mask])
# 4. Discard the rest (Zap!)
return kv_cache
The memory savings would be immediate. Instead of allocating a 128k block, the memory manager could dynamically allocate smaller blocks based on the “density” of the conversation.
The “Compatibility” Check
One of the reasons I’m bullish on KVzap is that it satisfies the “Four Criteria” NVIDIA set out for adoption:
1. Fast: The MLP overhead is <1%.
2. Phase-Agnostic: Works for both Prefilling (reading the prompt) and Decoding (generating the answer). Most methods fail at one or the other.
3. Optimization-Friendly: Compatible with FlashAttention2.
4. Faithful: Preserves reasoning capabilities.
The Future: End-to-End Pruning
While KVzap is a massive step forward, the authors admit it’s still a “Post-Hoc” solution. They trained the model after the fact to predict scores.
The holy grail is End-to-End Training. Imagine a model like GPT-6 that is trained to zap its own cache. During pre-training, it would learn that “If I generate a boring token, I should also generate a ‘delete me’ signal.”
This concept, sometimes called DMS (Differentiable Memory Selection), is already being explored. But until we get those next-gen architectures, KVzap is the best bridge we have.
Final Verdict
I’ve been skeptical of KV cache pruning for a long time. It always felt like a dangerous shortcut—like trying to save gas by turning off your headlights at night. You might save resources, but you’re likely to crash.
But KVzap feels different. By training a specific surrogate model to mimic the attention mechanism, NVIDIA has turned pruning from a heuristic guess into a learned optimization.
If this lands in the next vLLM release (and I suspect it will, given NVIDIA’s involvement), we’re about to see a massive jump in what’s possible on single-GPU setups. We might effectively double the usable context window of our cards overnight.
The days of OOMing on a 100-page PDF might finally be over.
Key Takeaways for Developers
- Watch the Repo: Star
NVIDIA/kvpresson GitHub. This is where the code will drop. - Prepare for vLLM Updates: Keep an eye on vLLM pull requests for “Surrogate Model” or “Dynamic Pruning” support.
- Don’t Trust Old Pruners: If you’re using H2O or simple eviction policies for complex RAG tasks, benchmark them using RULER. You are likely losing accuracy without realizing it.


