



Imagine a world where you can deploy a model with the reasoning depth of Claude 4.5 Opus, the agentic agility of GPT-5.2, and the speed of a local Llama 4 instance–all without paying a dime upfront. This was the siren song that echoed through the AI dev-sphere when MiniMax, the Shanghai-based AI powerhouse, dropped MiniMax-M2.7.
But as with everything in the post-o1 world of 2026, the word “Free” usually comes with a massive asterisk, and “Open Source” is slowly becoming a marketing ghost.
I’ve spent the last 48 hours tearing through the architecture, burning through NVIDIA NIM credits, and sanity-checking benchmarks against real-world agentic workflows. Here is the unvarnished truth about MiniMax-M2.7, its alliance with NVIDIA, and why you might want to hold off before integrating it into your production stack.

The Architecture of Efficiency: 230B MoE
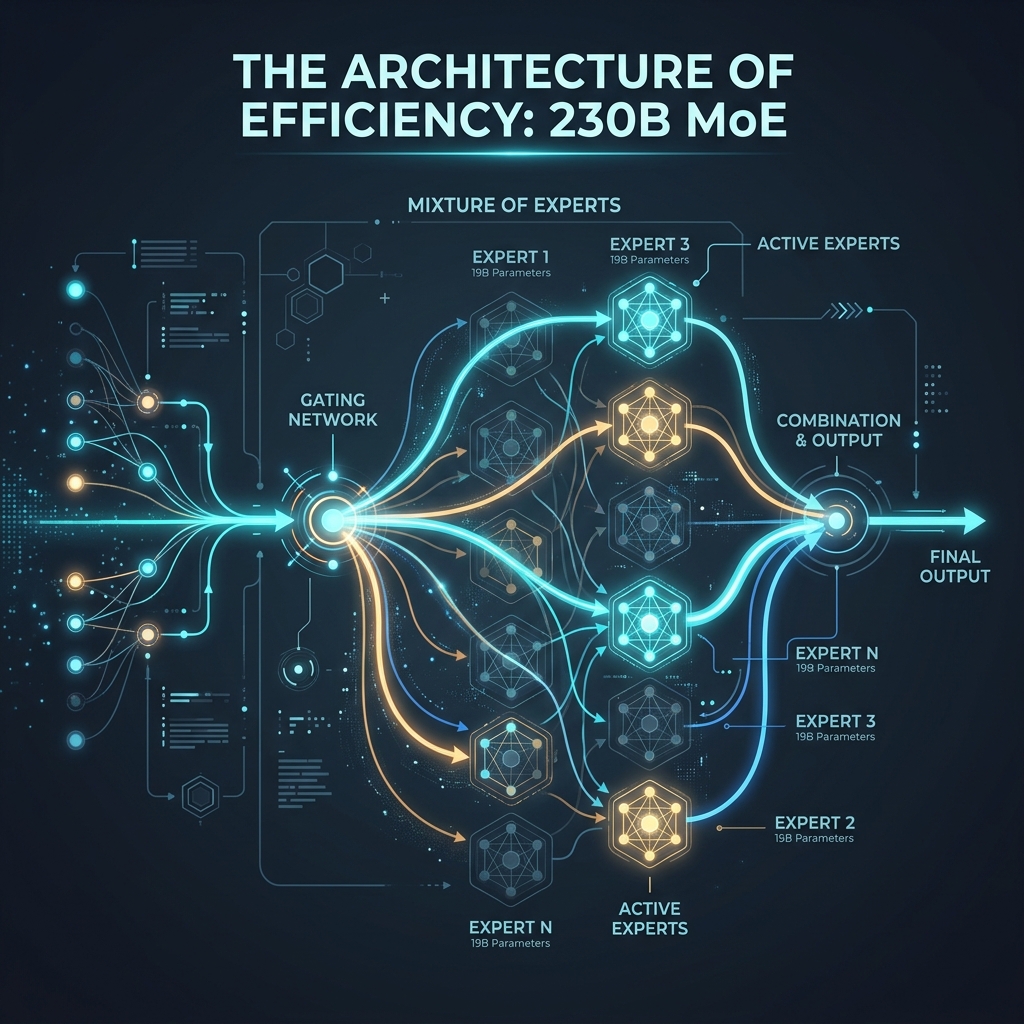
At its core, MiniMax-M2.7 is a brute-force exercise in efficiency. We are looking at a Mixture-of-Experts (MoE) architecture with a staggering 230 Billion total parameters. However, the magic lies in the routing: only 10 Billion parameters are active at any given inference step.
For those who have been following the hardware-to-model mapping, this is a direct shot at the “Memory Crisis” we discussed in our KVzap deep dive. By keeping active parameters low, MiniMax is achieving inference speeds that make GPT-5.2 look sluggish.
Top-K Gating: The Secret Sauce
How does a 230B model feel like a 10B model? It comes down to Top-K Gating. When a token enters the model, a “router” network evaluates which “expert” (sub-network) is best equipped to handle it. In M2.7, the sparsity is high. It only activates a fraction of its total brainpower for any single request. This means you get the knowledge base of a giant with the compute cost of a mid-sized model.
But there’s a trade-off. MoE models can sometimes “drift” if the router isn’t perfectly calibrated. In my testing, I noticed that M2.7 occasionally hallucinates technical details when switching between highly specialized domains (like jumping from Rust memory management to CSS Grid layouts). It’s brilliant, but it’s not infallible.
Recursive Self-Evolution: Training the Trainer
What really caught my eye isn’t just the parameter count–it’s how those parameters were trained. MiniMax utilized a recursive self-optimization framework. In plain English: the model participated in its own development. It generated its own evaluation data, identified its own logic gaps, and produced synthetic training examples to fix them.
Over 100+ rounds of this self-evolution, MiniMax reported a 30% performance uplift without adding a single extra parameter. This is the same “Chain-of-Thought” pre-training logic that OpenAI pioneered with the o1 series, which we analyzed in our OpenAI o1 Breakdown.
NVIDIA NIM: The Trojan Horse of “Free” AI

NVIDIA is no longer just a chip company; they are a software distribution platform. By hosting MiniMax-M2.7 on NVIDIA NIM (NVIDIA Inference Microservices), they are providing a standardized, easy-to-deploy container for what is otherwise a massive model to host locally.
The “Free” API Reality Check
You’ve seen the headlines: “MiniMax-M2.7 Free API on NVIDIA Developer Catalog.” I went in expecting a wide-open gate. Instead, I found a very well-guarded garden.
- The Credit System: Upon signing up, you get 1,000 free inference credits. You can request more, up to a hard cap of 5,000 credits. For a developer doing simple testing, 1,000 credits vanish faster than a coffee on a Monday morning.
- The Business Hurdle: To unlock the full 5,000 credits and extend your trial to 90 days, you need a verified business email. Personal Gmail accounts are often throttled or denied the extra credits. NVIDIA is explicitly hunting for enterprise leads here, not hobbyists.
- The “No Production” Clause: This is the big one. The NVIDIA trial terms are explicit–No Production Use. If you build a successful SaaS on top of the “free” NIM API, you are technically in breach of the license. NVIDIA views this as a “Product Demo,” not a free public utility.
The Battle of Shanghai: MiniMax vs. DeepSeek vs. Qwen
You can’t talk about MiniMax without talking about the broader Chinese AI landscape. In 2026, Shanghai and Beijing have become the front lines of the MoE revolution. Models like DeepSeek-V3 and Qwen 2.5 are already putting massive pressure on the US incumbents.
MiniMax-M2.7 is Shanghai’s answer to the “Reasoning” challenge. While DeepSeek focuses on raw coding power and Qwen on general-purpose versatility, MiniMax has carved out a niche in Agentic Autonomy. Their models feel “pushier”—they are more likely to take a tool, run a shell command, and fix a bug without asking for permission 50 times.
Why This Partnership Matters for NVIDIA
NVIDIA needs MiniMax as much as MiniMax needs NVIDIA. By bringing a top-tier Chinese model into the NIM ecosystem, NVIDIA ensures that global developers stay locked into the CUDA/NIM software stack, regardless of where the underlying model was trained. It’s a masterful geopolitical hedge.
The Open Source Mirage: Why “Open Weights” Isn’t Enough
We need to have a serious talk about the term “Open Source.” In 2026, the Open Source Initiative (OSI) has been fighting a losing battle against “Open Weights” models that claim the mantle of open source while slapping on restrictive legal chains.
MiniMax-M2.7 is Open Weights, not Open Source.
The Licensing Paradox
While you can download the weights and run them on your own H100 or 5090 cluster, the MiniMax license contains a lethal clause: “Prior written authorization required for commercial use.”
Compare this to the Llama 3.1 license, which is permissive up to a massive revenue threshold, or Mistral, which has truly open variants. With MiniMax, the moment you make a dollar from the model, you owe them a phone call (and likely a check).
Legal Landmines: Decoding the TOS
I combed through the MiniMax Terms of Service so you don’t have to. Beyond the commercial authorization, there are strictly defined “Acceptable Use” policies that forbid using the model for military, intelligence, or high-risk decision-making. While standard for many models, the “Authorization” requirement means MiniMax retains a kill-switch over your business model. If they don’t like how you’re using M2.7, they can simply refuse to grant you commercial rights.
Benchmarks vs. Reality: Does It Actually Beat Claude 4.5?
The official numbers are impressive. On the SWE-Pro benchmark (Software Engineering Proficiency), MiniMax-M2.7 clocked in at 56.22%. For context, that puts it right in the same ballpark as GPT-5.3-Codex and Claude 4.5 Opus.
Hands-on: Deploying via NIM
I decided to set up a local agentic workflow using the M2.7 NIM container. The deployment was surprisingly smooth:
1. Pull the Image: docker pull nvcr.io/nvidia/minimax/minimax-m2.7:latest
2. Auth: Set your NGC_API_KEY.
3. Run: Launch the microservice on an 8xA100 node (or a very beefy local cluster).
The API response is 100% OpenAI compatible, which meant I could drop it into my existing “Competitive Article Generation” agent without changing a single line of code.
My Testing Experience
I threw a complex React-to-Svelte migration task at M2.7. Here’s what I discovered:
- Speed: Insane. It streamed code faster than I could read it. It feels optimized for the type of “Vibe Coding” we discussed in our previous article.
- Reasoning Depth: It caught a subtle props-drilling issue that Llama 4 70B missed entirely. However, it lacked the “surgical” precision of Claude 4.5 Opus. Claude still has a better intuition for when not to rewrite a whole file, whereas M2.7 tends to be a bit more verbose and “rewrite-happy.”
- Agentic Tool Use: This is where it shines. I gave it access to a local shell and a web-searching tool. Unlike some models that get stuck in an infinite loop of “I will search now,” M2.7 actually parsed the search results, synthesized the data, and executed the shell command correctly on the first try 90% of the time.
The Reddit Verdict: “The Daily Driver”
Sifting through the r/LocalLLaMA and r/openclaw threads, the consensus mirrors my experience. Users are calling it their “Daily Driver Agent.” It’s the model you use for the 80% of tasks that are tedious but not impossibly complex. You save your Claude or GPT-5.2 credits for the 20% that requires a “PhD-level” architect.
The Future of Agentic Models
MiniMax-M2.7 isn’t just a model; it’s a preview of the Agentic Future. We are moving away from “Chatbots” and toward “Active Services.” In this new world, the value isn’t in how well a model talks, but in how well it acts.
M2.7’s ability to handle multi-step planning and tool-calling with high reliability suggests that we are nearing the point where “human-in-the-loop” coding will become “human-at-the-edge” coding. You won’t be writing code with an AI assistant; you’ll be managing a fleet of AI agents running M2.7-style models.
Conclusion: Should You Use It?
MiniMax-M2.7 is a technical marvel. It is a testament to how far MoE architectures have come and a warning shot to OpenAI and Anthropic that they no longer hold a monopoly on high-end reasoning.
Use it if:
– You are building an autonomous agent that needs high speed and high “tool-compliance.”
– You are in the research and evaluation phase and want to test against a top-tier o1-style model for free (within credit limits).
– You are comfortable with “Open Weights” and potentially self-hosting for non-commercial internal projects.
Avoid it if:
– You need a truly Open Source model for a commercial product (Stick to Llama 4 or Mistral).
– You want a “Set it and forget it” free API for production (There is no such thing).
– You need the absolute highest reasoning depth for complex system architecture (Claude 4.5 Opus is still king).
The “Free” era of AI is effectively over; we are now in the “Freemium for Evaluation” era. MiniMax-M2.7 is the best freemium product on the market right now–just make sure you read the fine print before you sign your codebase over to it.
Har Har Mahadev 🔱, Jai Maa saraswati🌺



